Forensic Explorer V5.2 - GetData
by Jon Munsey - Last Updated 21st May 2020
1. About This Review:
 GetData Website - Circa 2004
GetData Website - Circa 2004
Today things look virtually the same, I guess if its not broken, don't fix it;
 GetData Website
GetData Website
The product page for FE can be seeen here and below, notably its a bit out of date - not showing screenshots from the current version of FE....thats odd:
 Forensic Explorer Product Page
Forensic Explorer Product Page
-
Live Boot: Boot forensic image files, including Windows (all versions) and MAC. Learn more about Live Boot.
Shadow Copy analysis: Easily add and analyze shadow copy files. Learn more about Forensic Explorer Shadow Copy Volumes.
-
Customizable Interface: The forensic explorer interface has been designed for flexibility. Simply drag, drop and detach windows for a customized work-space. Save and load your own work-space configurations to suit investigative needs.
-
International Language Support: Forensic Explorer is Unicode compliant. Investigators can search and view data in native language format such as Dutch or Arabic.
-
Complete Data Access: Access all areas of physical or imaged media at a file, text, or hex level. View and analyze system files, file and disk slack, swap files, print files, boot records, partitions, file allocation tables, unallocated clusters, etc.
-
Fully Threaded Application: Run multiple functions and scripts in threads.
-
Multiple Core Processing: Maximize PC processors for intensive functions like keyword searching, data carving, hashing, signature analysis.
-
Powerful Pascal Scripting language: Automate analysis using a provided script library, or write your own analysis scripts. Automate tasks such as:
- Run skin tone analysis on graphics files;
- Extract user, hardware system information from the registry;
- Locate and analyze transcripts from Internet chats; etc.
-
Data Views: Powerful data views including:
- File List: Sort and multiple sort files by attribute, including, extension, signature, hash, path and created, accessed and
modified dates.
- Disk: Navigate a disk and its structure via a graphical view. Zoom in and out to graphically map disk
usage.
- Gallery: Thumbnail photos and image files.
- Display: Display more than 300 file types. Zoom, rotate, copy, search. Play video and music.
- Filesystem Record: Easily access and interpret FAT and NTFS records.
- Text and Hexadecimal: Access and analyze data at a text or hexadecimal. Automatically decode values with
the data inspector.
- File Extent: Quickly locate the location of files on disk with start and end sector runs.
- Byte Plot and Character Distribution: Examine individual files using Byte Plot graphs and ASCII character
distribution.
-
Categorize and Custom Filter:
- Filter any list view to show folders and files that match a set criteria. Script your own filters.
- Display files in Categories view where files are grouped by extension, signature, attribute, etc.
- Quickly flag files of interest.
-
RAID Support: Work with physical or forensically imaged RAID media, including software and hardware RAID, JBOD, RAID 0 and RAID 5.
-
Use an inbuilt data carving tool to carve more than 300 known file types or script your own. Learn more about Forensic Explorer data carving.
-
File Signature Analysis: Forensic Explorer can automatically verify the signature of every file in a case and identify those mismatching file extensions.
-
Registry analysis: Open and examine Windows registry hives. Filter, categorize and keyword search registry keys. Automate registry analysis with Regex scripts.
Recommend Requirements:
- Forensic Explorer and Mount Image Pro are optimized for an Intel® Core i7 with 16GB RAM.
- Forensic Explorer is 64bit application (32bit is available on request).
- Supported Host Operating Systems are Windows 7, 8, 8.1 or 10.
Supported File
Formats:
- Apple DMG
- DD or RAW;
- EnCase® (.E01, .L01, Ex01);
- Forensic File Format .AFF
- FTK® (.E01, .AD1 formats);
- ISO (CD and DVD image files);
- Microsoft VHD
- NUIX File Safe MFS01
- ProDiscover®
- SMART®
- VMWare®
- XWays E01 and CTR
Supported File
Systems
- Windows FAT12/16/32, exFAT, NTFS,
- Macintosh HFS, HFS+, APFS
- EXT 2/3/4
- Hardware and Software RAID: JBOD, RAID 0, RAID 5
Email Analysis Formats:
- Email module supports the analysis of .OST and .PST files.
- The Index Search module (DTSearch) supports the index and keyword search of .OST and .PST
files.
Additional Formats & Supported Features:
I've spoken with GD as there seem to be some glaring omissions from this list and they confirms that the following additional formats are supported;
- LX01 (Encase logical image files V2)
- AD1 (All versions - there are around 3) however encrypted images are not supported
- VHDX and VMDK disks.
- AFF3 and AFF4 disk images.
- Macquisition Disk Images
There is also support for running FE on Windows Server 2016 and 2019 (which is not listed, but GD state it runs fine).
So thats a pretty decent feature set, more is being added all the time - to the point of where I can't keep updating this page !! RAID6 was recently added to the supported disk structures, as was various old and new E-mail container files.
Check their change log regularly as the website blurb lags behind.
Ok, lets not linger here - I am not a fan of marketing schpeel, the proof is in the pudding.....
Feature Section Summary: EXCELLENT - I can't believe all of this is here for the price.
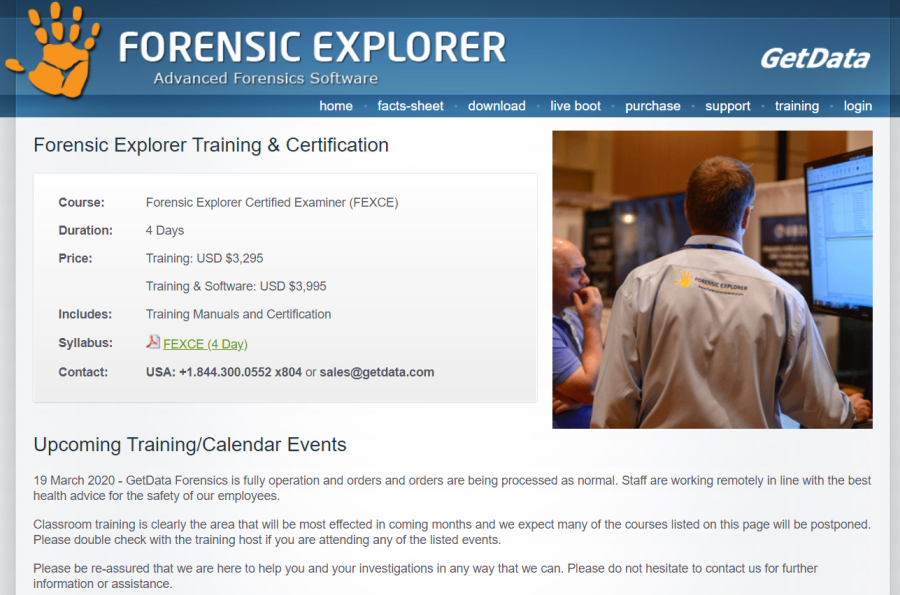 FE Website - Training Page
FE Website - Training Page
For a 4 day training course that is a complete bargain (but please don't put the price up after reading this!) - and when you choose to purchase the software at the same time, its a blo*dy steal.
Compare this pricing to other vendors (I am looking at you Magnet and Guidance/OpenText) at the single course price point, and you can see the value here. The problem with large corporates is that anything they sell must support their infrastructure - which is why training is so costly. Smaller vendors don't have those overheads - hence products and training can be much cheaper in certain circumstances.
There is an examination (test) at the end of the course and a subsequent certificate issued, which is always nice to have in your CV/resume.
I have not been on any of these training courses, so ultimately I can't give you any guidance as to the quality, but it looks good from the documentation - and as you know by now - I have an eye for detail.
Training & Learning Section Summary: EXCELLENT - Right price, right content.

Ah, I remember when this first came out, it was awesome that you could mount DD images and .E01's, then later came the ability to mount .L01's and then .AD1's..... there is a lot of programs out there that do similar things, but for me, MIP will be the grandaddy.
I personally use Arsenal Image Mounter for physical image mounting as I find that MIP can be untidy when dismounting and can cause things to pile up in the registry when used heavily on a forensic workstation, code that needs looking at GD.
Don't get me wrong, MIP is a great product with a lot of pedigree - it will serve you well!
10. Installation & Uninstallation:
System Requirements Explored:
GD play it safe when saying that FE "is optimized for i7 processors" which is likely to lead some potential customers into thinking that an i7 is mandatory or it will run like a slug on anything else. That's just a recommendation - as long as you have 4 physical cores an Intel i5 (or equivilent) with a high clock speed FE will run just fine.
The bottle neck of any forensic workstation is usually disk I/O or memory, but that is another article
entirely and one of my favourite subjects (computer hardware).
Due to the pandemic I had to leave all of my nice toys at the lab - so I was testing on a 3rd Gen i5 CPU (quad core), with 12GB of RAM and a very large page file. I had a dedicated mechanical drive for images and another for the FE case file (and database), FE itself and the OS was installed on an SSD.
This would usually equal a very unresponsive system, but other than the indexing side of things (more on that later) I was very impressed with how responsive FE was. I won't bore you just yet with screenshots of RAM and CPU usage....
ProTip: i3 CPU's suck, i5 CPUS's are amazing value if you purchase one which has "full fat" four physical cores (watch out as some of the low/mid range i5's have 4 threads and only 2 (Dual) physical cores). Also avoid low power variants of any Intel CPU (usually with an U, S or L suffix to their model number) - as those tend to have a very low clock speed - which also kills processing/indexing speeds.
These lower power CPU's also can't maintain their "Turbo" boost to the clock speed for very long, so when running long cpu intesive tasks they clock back to their much lower "sustained" cpu speed. These low power variants are only usually found in laptops, but some workstations offered them to be eco friendly. You can read more on i5's here (quad cores start with Sandy Bridge) and if you want to see a video with Linus explaining the difference between i3, i5 and i7 go here.
If you are really interested in why i7 is a waste of money (relatively and subjectively speaking) go here and see how an i7 laptop was just 10-15% faster than an indentical i5 equipped machine (7th gen chips). Its a bit subjective, but you don't need the fastest CPU on the planet to get a responsive system.
For the AMD fanboys, the best buy at the moment is arguably the Ryzen 7 2700X (2nd Gen) or the current Ryzen 5 3600X (as fast as the 2700X), if you are looking for bang for buck on a forensic workstation that you propose to use with FE. Full reviews and benchmarks of those CPUS in the orange clickable links!
If you are looking to buy a turn-key forensic workstation, you won't do much better than buying one from Sumuri, their Talino Workstations are very well respected and have insanely long warranty periods - so check them out here.
Alternativel if you are a hardware nut like me, don't have the budget for a Talino and would be comfortable with buying ex-lease corporate equipment (which needs a lot of setting up and configuration) you won't go wrong buying from Bargain Hardware - tell them I sent you! I will be doing an article soon "Forensic analysis & processing on ex-lease server" so be sure to subscribe to be notified when that drops.
Installation & Uninstallation Section Score : EXCELLENT - No problems here.
 FE Splash Screen
FE Splash Screen
 FEC Launch Screen
FEC Launch Screen
Hang on, I don't remember it looking like this - I've just gone and looked at the manual for V3.x and yep, it had this interface way back in 2015, just shows you how little attention I have been paying to this product over the years.
Don't get me wrong, I like it, its somewhere between Encase's "I can't find anything" and FTK's "9 million menu items to choose from" interfaces - both of which are total garbage. So this looks ok at first glance.
If an Interface is Trash - You get used to it:
After 15+ years of using FTK and EnCase every day, the neurons in my brain have burnt a path so I know where everything is. I guess thats the only way you can get away with having a sh*tty GUI is having customers stay with you for over a decade.
Why do I stay with tired old products that have been completely superceded by other vendors products ? Cheap renewal fees - thats why. Until I can no longer do a decent job with those two tools, in a reasonable time frame, I'm standing pat - I do have a lot of other tools I use - but these two suit my case type (the who did what when type).
12. Testing - Exploring FE's Tabs:
So loading up an image of a bog standard Windows machine, formatted with NTFS gives us this - click to zoom;
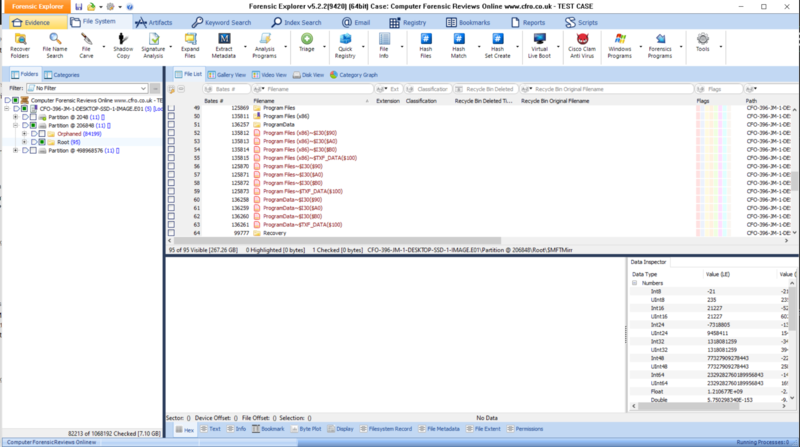
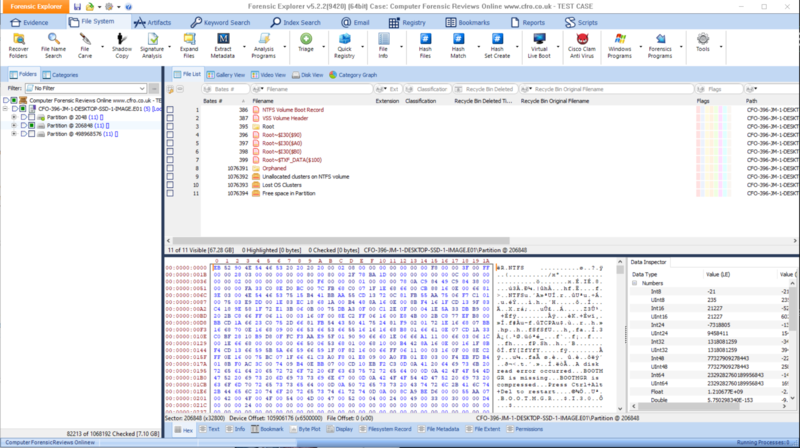
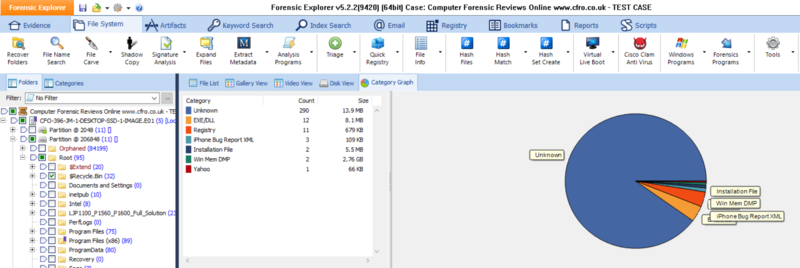
I'm Not 1337 Are You ?
As you may have noticed from the screen-shots above, FE is certainly a "hard-core" tool - especially when displaying the contents of the file system, this reminds me of Paraben's E3U and other vendors, where you can really get an unfiltered view of the file system. Customers who are "on the spectrum" are going to love the level of detail on offer here.
Budding examiners however, are going to find this view hard going (as everything you see that is in red will have you trying to remember what your mentor or the text books said about them!). You will also kick yourself when you forget to "untick" or filter out these metadata entries when you want to export files out of FE or run reports and charts.
Tabbed Interface:
FE neatly segregates its key features into tabs, Evidence, File System, Artefacts, Keyword Search, Index Search, Email, Registry, Bookmarks, Reports and Scripts.
This is super clear, you are not going to get lost if you stick to these tabs - this is one of the better interfaces I have seen (Although BelkaSofts Evidence Centre is still my favourite - but don't tell Yuri his head will get big....) - with Axiom a close second - don't even start me off on FTK or EnCase's interfaces as they are terrible.
Evidenence Tab:
We are skipping the Evidence tab as thats a given (but we will come back to it later when its more relevant), so lets move onto something more interesting....
File System Tab:
The first screenshot above on the carousel is showing you folders that don't actually exist in the file system, these are psuedo folders that FE is using to allow it to present the file system in some form of hierachry. It is not a criticism to see these things here (such as root folders, streams, zone identifiers, index entries etc..etc..) - they are needed, but a dial or some kind of sanity filter would be nice to dial this back a little in my opinon.
Some times I just want to see things like Windows Explorer does. If GD get in touch about this, I will update this comment!
If you are used to adding an image into EnCase and opening up the partitions to see the file system - you will need to familliarise yourself with the way FE presents this information. For example, partitions are not numbered or given volume labels (see below carousel), they are listed in the order they appear on the disk and at the sector offset (from 0) where they begin on the disk (This confirms to me that all GD developers have binary wrist watches and nixie clocks on the wall *giggle*).
QOL improvement request: Can we please have the volume label here in addition to the offset, as this is going to get mighty messy if you come across a disk with more than a handful of partitions (for example a server with many volumes - names are easier to remember over sector offsets).
Its quick to learn what you are being shown in FE, but to reiterate - many examiners who don't see this level of detail in their current tool may find it a case of information overload when navigating the file system.
Clutter Clutter, Clutter.....
FE displays a number at the end of each line showing what it thinks is a useful number of items that the folder contains, see below;
I'm not a fan of this, its pointless in my opinon - I would like to see filter button that would remove metadata entries from these counts, making the feature actually useful for seeing how many "real" files and folders exist within any given folder.
Verifying File Signatures Is Mandatory:
Normally, you may not bother to do this in other tools, as they "know" where the Chrome History database lives and how to recognise it, but FE doesn't, so if you click the "Artefacts --> Chrome History" feature, it will start parsing - but in reality the wheels spin but ultimately, nothing happens.
If you read the manual, you won't fall into this trap, but noting that FE did not have any validation here to detect you had not ran the required file signatues script was surprising.
I would like to see a couple of lines of code added to validate whether you have run file signatures across the files you have pointed an artefact script at, to save new users from waiting for scripts to execute that won't return anything other than a blank screen and no error message.
If you run the file signature analysis first, then re-run the Chrome History feature, boom, the sql databases .db files are parsed and the lights come on in FE's artefact page.
So keep that in mind if you take out a trial of FE - as it works in a slightly different way to other tools you may have come across in the past.
Clever Programming - Parse Once - Not Many:
FE keeps a database of what files are in the image, as soon as you "do something" (such as a hash, or file sig analysis) this database is updated (a flag is set). So if for example, you choose to examine the WhatsApp data within an iTunes backup, the manifest for that iTunes backup file is parsed and cached.
If you then decide you want to examine something else inside that iTunes backup file, FE remembers it has already parsed the manifest for that file so does not make you wait eons whilst it repeats an entire reparse of the manifest file for each artefact you want to pull out of the iTunes file.
Its a small point, but little things like this are great QOL improvers!
Data Mapping & Graphs
One of the nice features I like about FE is that you can display the contents of any folder (or an entire disk) as a chart, this is a great way to display visually what is on a disk or piece of media. This feature has been in FE for a very long time, long before other tools added this kind of visualisation to the best of my knowledge.
Its a little rough around the edges (I found that the labels for data types overlapped each other - but maybe that was my screen resolution or a setting I needed to change somewhere) but this is a really useful feature for reports or client presentations. There are over 20 different types of graphs, so there is a lot of choice on offer here.
I know certain E-Discovery firms that built their own tools to do this at immense cost - so seeing it baked in here is nice.
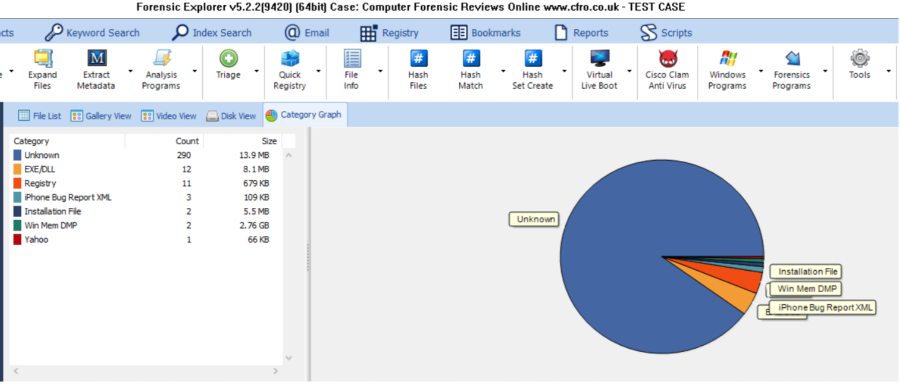
Summing Up:
We are not all Stephen Hawking, so I would like to see the "hardcore" file system entries filtered out by default, and those super slueths among us can turn them on when needed.
I have to say that FE is super responsive, I mean lightning fast in relation to navigating around the folder structure, home plating (I'm an Encase old person) and sorting. Everything was stored on mechanical drives - not even the database was stored on an SSD.
Try doing stuff like this in EnCase and you will be waiting a few seconds whilst the program stops responding while you wait, try it in FTK on truly massive file listings, you will be waiting even longer. So performance wise FE scores very highly here.
It looks like FE has really well optimised code in this respect, which is defintely a plus and reduces stress when using it!
File System Tab Section Summary: EXCELLENT - Stellar performance - one of the most responsive tools I've ever used.
Artifacts Tab:
FE has a compiled core and a series of scripts (written in good old Pascal) which are used to carry out all but the most basic tasks. See those "Browsers", "Chat", "Mobile" and other icons on the tool bar below - they are full of scripts you can run.
 Artefacts Tab
Artefacts Tab
Pascal/Delphi is an odd choice (its not a contempary language in my opinion), but I guess it is easier than using something like C#. In a way it makes sense to use an established language for scripting, rather than create something entirely new as other vendors did (Such as Guidance with EnScripts) in the past.
I grew up at college with Borland Turbo Pascal, so examining FE's visible code is like seeing an old friend again! Ahh, the MSDOS days of non-maskable interrupts and real mode - where the machine was truly yours to command - I digress, sorry!
Going back to the heavy use of scripts in FE..... FE's core (the program you see when you load FE) has no idea how to parse the contents of for example, a Chrome web history "webvisits.db" (a sqllite database file) file when you click on it.
There is no instantly available "view" tab, that will let you switch between views (such as Hex, Transcript or Doc in Encase or Natural, Web or Media in FTK) of most things that have not had a script ran over them.
A script must be executed first, compiled and ran over the data before you want to examine BEFORE you can view the data - its pretty logical really, so not a criticism.
This is a concept/principal that you will need to learn to get the most out of FE, if you don't, you are going to miss stuff and think something is broken.
Take a look at the carousel of screen-shots below, where you can see the myriad of Artefacts that FE can parse:








Artefacts fall under the following categories (check the above carousel for a detailed view)
- Web Browsers
- Instant Messaging Clients (Chat)
- MAC OS
- Windows
- Social Media
- Carved (from Unallocated clusters)
- Mobile Artefacts
We will touch on some of these on the way through the review, but as stated previously I was unable to test all functions of the sprawling metropolis that FE is.
Artefacts are in a Mess and need Urgent Work:
This is an area of FE that to me appears to require more resources to maintain than GD have available, artefacts are confusingly named and do not list which operating system (or program versions) the script is compatible with. You can't look in the manual for help at present either - as that section is missing at the time of writing this section of the review.
Whilst the author of many of these scripts has dilligently attempted to list sources used for the manner in which any given artefact script parses - this is usually long out of date and referring to older operating systmes, such as Windows XP and Vista.
As a minimum, FE should be focussing on Windows 7 to 10 as the percentile of other operating systems in use is very small.
It seems that focus has been lost.
Easy Clean This Mess Up:
The way forward here is for FE to display a dialogue box each time a script is executed, which tells the user what to expect - or at the very least the comments in the summary that pops up when a script completes - is updated to show this information.
I had numerous problems with the accuracy of the information returned by scripts in the Artefact tab (we will cover some of those in the bugs section later). Running the "Microsoft Office 2010" MRU (recently opened files scripts) is a good example of this - we are in 2020, Office is at 2019/365 - so enough said here.
I'm seriously unimpressed and my awe of FE's performance thus far has been somewhat damaged.
Artefacts Tab Summary: Below Average - Looks amazing on the surface, but when prodded is full of poorly labelled, out-dated or broken scripts.
13. Testing: Forensic Explorer Imager V2.0





Looks good doesn't it ! You can image to .E01 or .DD for physical disks and for Logical images you can create Encase .L01 files (I couldn't find any support for creating .AD1 files). Speed is excellent (well done to GD's dev's for improving the god-awful V1.0 that shipped with FE previously!).
It is possible to make a live image, which is great - meaning you can run FEI on your suspect machine, whilst booted into its operating system in the same way as you can with FTK Imager Lite.
ProTip: Whats a live image ? Its an image of the computers hard drive taken whilst the computer is powered up and booted into its operating system, the image is obtained by running an imaging tool such as FE Imager directly from that booted operating system. You will need local admin privileges for this to work (otherwise FE Imager and all other imaging tools won't be able to open the hard drive for direct access at sector level).
Live imaging is not the most forensically sound process in the world, but in some cases it is the best image available.
Live images are used when you can't log the user out or power the machine off to make the image in the traditional way (removing the hard drive and using a write blocker or booting it from a USB stick and using a forensic operating system such as CAINE, WindowsFE (forensic edition) or even this newer Windows 10 PE based solution).
ProTip: When making a Live image of a powered on computer, be very careful to check if there is any whole disk encryption (such as Bitlocker) active. If there is, my advice is to make a logical image of each drive separately (C:, D: etc...) as opposed to doing the usual physical image to capture the whole drive. Check with your mentor if you are unsure if a logical image of this type is the way forward if unsure.
If you go down the logical route, you will still obtain unallocated clusters within the volume/partition you chose to image - with the added bonus that the image will be in a decrypted form when you try and add it into a tool such as FE or Encase.
If you decide to gamble and use the "Physical" option, be prepared to provide the BitLocker recovery key (or other key) when you try to open the image - as it will still be in an encrypted state - which is another article in itself. So just remember - live image = logical volume image.
For clarity, when I say logical image, I don't mean make a .L01 or .AD1 image containing just the files - the logical image I am talking about is a sector-by-sector copy of each logical partition/volume on the suspect disk..
Gotcha!: I noted that whenever I tried to open a logical EnCase evidence file in EnCase (a .L01) that I had created with FE Imager V2 - I received "Error in header integer" errors from EnCase V8.12 - errors like this usually mean the file is damaged in some way.
An update to the manual explaining this or a fix is required here urgently. I have reached out to GD for comment - so will update this section once I hear back. Notably FTK 7.2 did not complain when ingesting these .L01 files - however I expect its vetting and verification of the .L01's structure is less robust and more forgiving than EnCases.
Poor Logging:
Whilst FEI 2.0 does give you a log file once it has completed a task, this is lacking - for example when creating a .L01 logical image, there is no list of the files that were encapsulated in the image - crucial if you are acquiring data from network drives or other locations where permissions, network failures or other events may cause a file not to copy.
Improvement is needed here otherwise it is much safer to use verbose tools such as Robocopy of FTK Imager Lite - as usual GD has been made aware of this.
Final Thoughts:
Disk imaging has been sown up for a long time with FTK Imager and dare I say it Encase Imager (yuck) for Windows, with Guymager catering for the tin foil hat linux division of our forensic bretheren and the likes of Sumuri Recon ITR and Macquisition dealing with MacVellian branch.
I'm not sure I trust FE Imager 2.0 yet - getting errors when importing images into EnCase is not confidence inspiring. This reminds me of similar problems when importing GuyMager imagers into EnCase (cured with the "AvoidEncaseProblems" switch!). Whilst I understand the GuyMager errors, I have not dug out the hex editor to see what FEI is doing so can't comment any further.
FE Imager Summary: VERY GOOD - Would have been Excellent were it not that EnCase does not like FEI's .L01 files and the scantly populated log files - your guess is as good as mine as to how this got past internal testing protocols.
14. Testing : Image Conversion Tool

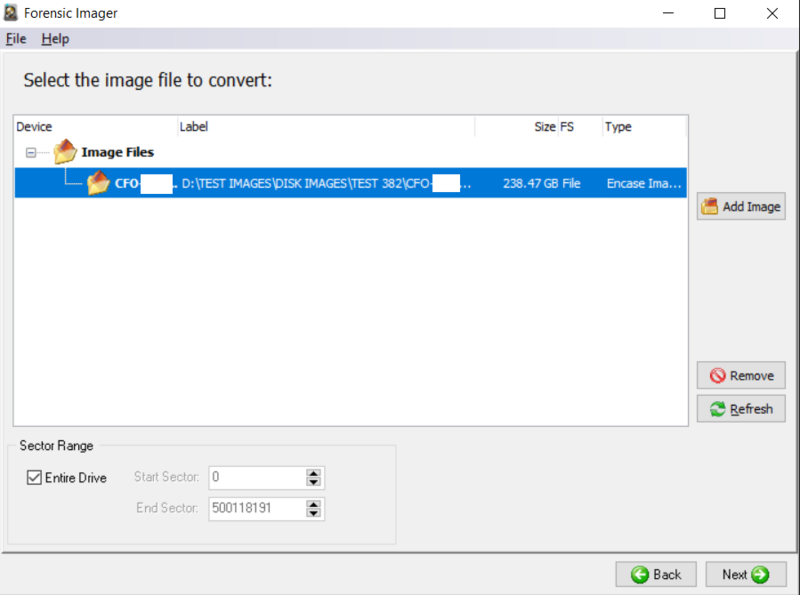

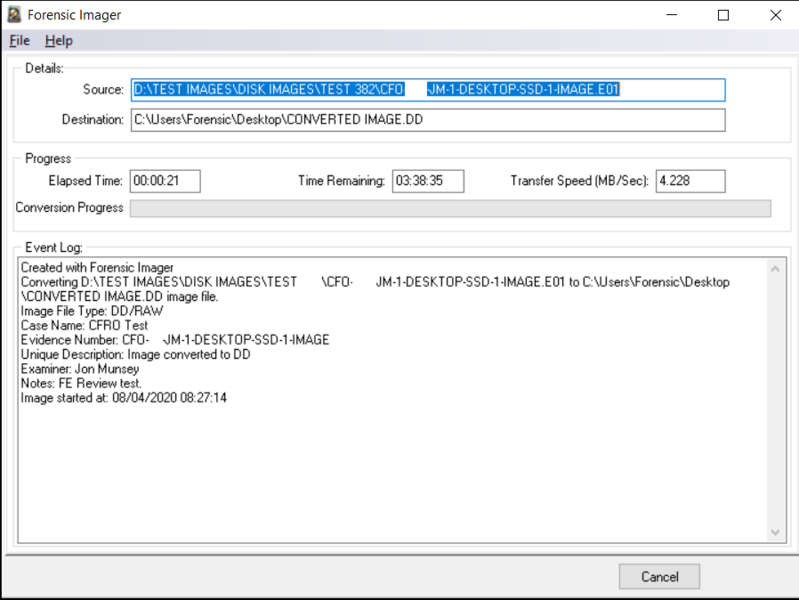
15. Testing - Triage Function:
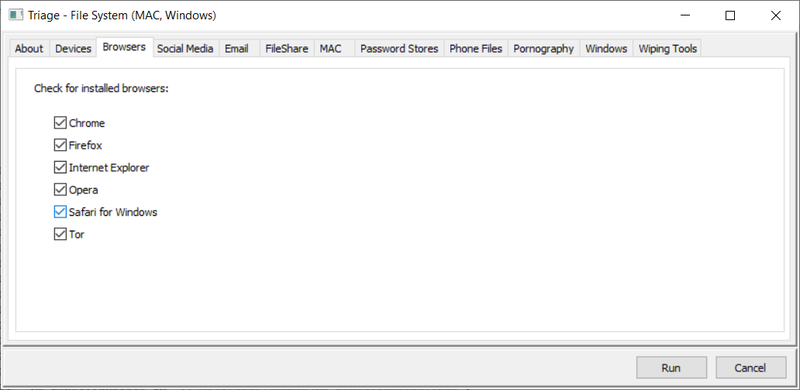
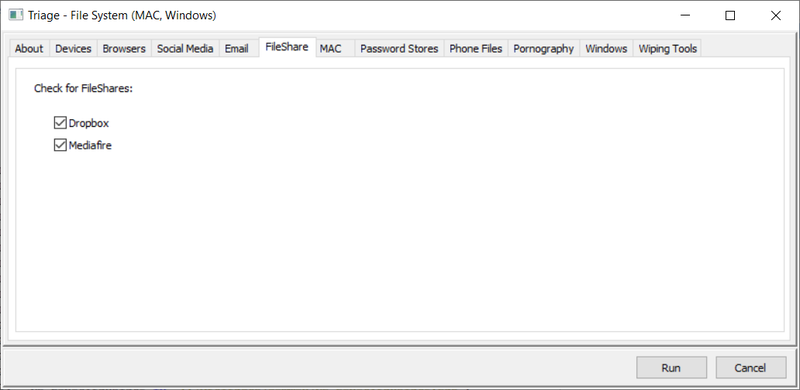
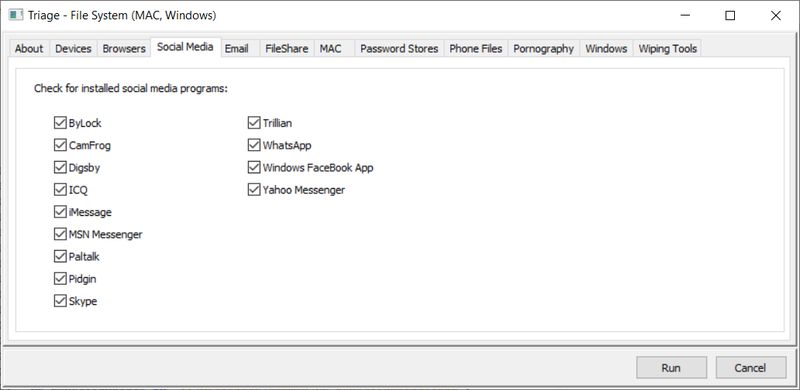
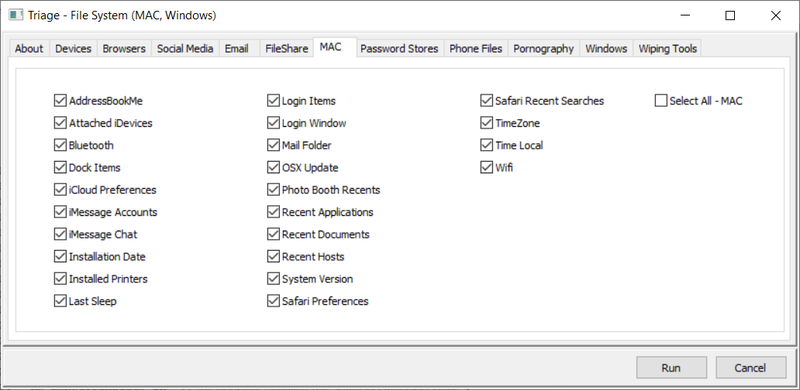

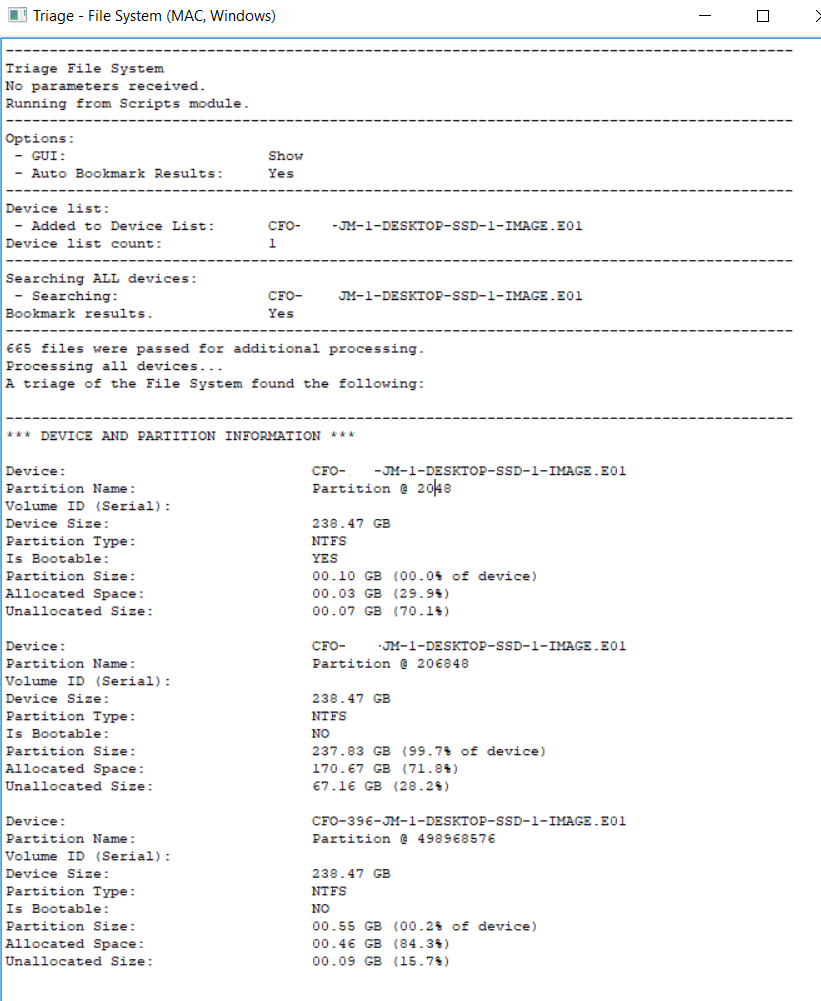 Triage Report Output - Page 1
Triage Report Output - Page 1
 Triage Report - Output Page 2
Triage Report - Output Page 2
Super Fast Triaging (But make sure you know why its so quick!):
As you can see (from the log above) this took 348 seconds (about 6 minutes) and has given me a pretty comprehensive report of what I can expect from this drive if I look at the file system manually, or if I put this into a dedicated artefact processor such as Internet Evidence Finder from Magnet. FE has its own artefact parser, but we will come to that later.
The two screenshots above may appear to be a bit spartan, but that is because it is a corporate machine which has not been used for anything other than Web browsing and Microsoft productivity applications.
Gotcha: You have to remember that FE is spending 5 minutes or so, looking at the file system of the image you are triaging. It is *NOT* (by design) opening internet history files, pulling metadata from link files, productivity documents or any other files or internally parsing their content (Like Internet Evidence Finder from Magnet would do as a comparison).
As an example, the FE Triage mentions nothing in relation to DropBox being detected - thats not quite true - as whilst there is no installation of the drop-box client software on this machine (FE Triage would find that), the user has been heavily accessing DropBox via the installed Chrome web-browser.
This is not a limitation or problem with FE, the onus is on the examiner here to ensure they know what the triage will and will not tell them.
Yet again, another reason to make sure you either take a training course or read the manual before using any of the features.
Polish will make Triage a Killer Feature:
I think it is a really good feature and hope that GD continues to expand this (they have been in touch to say they are working on the Triage function as I type!), with a bit of work, this module could be polished up to give the user the choice of the current "super high speed triage" or to run a deeper triage scan, to examine the data stored inside certain files the examiner chooses at the time.
Check their change log here is my advice to see what they added!
Triage Section Summary: Excellent - No problems here.
16. Testing : Artefact Processing Scripts:
As you may recall, FE has a dedicated Artefact tab (which I looked at briefly earlier and was unimpressed with) which allows you to run the built in scripts to parse files in the case and display the results. I didn't show you anything running from that tab, so here you go;



17. Testing - Live Boot:




Password, No Problem....Bypass It:
As we can see in the screenshots above, this user has a password that prevents their account from being accessed - so the boot process isn't going any further. Whilst this is not something we usually worry about when examining things from the other side of the glass (looking at the disk in Encase, Xways etc..), here it is!
I didn't test images that were Bitlocker encrypted, I assume booting those would drop the portculis Die-Hard style and lock you out of the boot process completely - requesting the Bitlocker Recovery Key - due to dissimilar hardware or lack of a TPM being detected.
Potted History of Windows Password Security: (you might want to skip this!)
As you may, or may not know, the password hashes for all users are stored in the Security Account Manager (SAM) file on the hard drive of the machine, which is part of the system registry. You can learn all about the SAM file here.
What windows is asking for at the logon box, is a series of characters to be typed in (a password), it then performs a mathematical operation on those characters to generate a hash. This hash is then compared to the hash stored in the SAM file for this user and if they match - boom, you get logged on.
When I was a young man, it was possible to brute force these hashes (in the days of Windows NT 4.0, pre Service Pack 3) by copying out the C:\Windows\System32\Config\SAM file and running it through L0pht Crack. The end result would be the password being recovered allowing you to log in. You can read more about L0pht Crack here. In those days, from memory, the encryption complexity of hashes was only 40-bit, which even for machines of the time, was not that hard to crack. You can also read about how weak the encryption was back in those days here (they chunked it into 7 character pieces which made it even easier to crack ).
Then along came Syskey, which Microsoft implemented to fend off these offline attacks described above. This made calculating the hash much more time consuming, effectively rendering cracking of complex passwords with a single machine extremely time-consuming. Remember, this was before the mainstream introduction of super fast GPU's, cloud computing or distributed password cracking. SysKey is dead, but you can read about it here if you wish!
Don't Crack it...Blank it.
Who remembers this ???? The offline NT Password editor ?
 Offline NT Password Reset Tool Website - Circa 2008
Offline NT Password Reset Tool Website - Circa 2008
In my I.T support days about 20 years ago, this saved my bacon so many times.....
 Offline NT Password Editor - Menu
Offline NT Password Editor - Menu
If you want to find out more about this tool, go here and check out the website, Pogostick.net is still up all these years later! Note that this has not been updated in a long time and support according to their website tops out at Windows 8.1.
Gotcha: If a user has used the Encrypted File System (EFS) feature of Windows (which came in with Windows XP) - where they right click a file, choose "Properties" and then choose "Encrypt", resetting the password using this utility (or Using FE's password bypass) will make those files permanently inaccessible.
These files are encrypted using a hash of the users login password, so when you click on those files in something like Encase etc, you will see just encrypted data. Whilst most tools support the decryption of EFS files (you just provide the logon password and the files are instantly accessible), its worth remembering!
In all my years of investigating over 1,000 computes, I have never seen anyone use this feature. EFS was the "thing" before Bitlocker and other whole disk encryption schemes came on to the scene. It was designed to protect your files if you laptop was lost/stolen and to prevent other users of the machine (with admin privileges) from viewing your files.
Back to FE......
Well, that is how it used to be done (bypassing and cracking Windows passwords), things have moved on now and FE has you covered.
For versions of Windows up-to and including 7, its a simple check box to reset a password so that you can log in to the image file you are booting - its that simple (you still lose access to anything encrypted with EFS (unless you obtain the users password), so watch out for that).
If you want to get technical on how this "blanking" is done, a value in the SAM file is set to a length of zero and this effectively blanks/removes the password from the user account of choice.
For contemporary versions of Windows, such as 10, things are a little more complicated, but it is still possible to reset the passwords of any local account. There is a very detailed guide for how to do this in the manual that accompanies FE, you will need some third party software which comes with FE- but once you do this one time, it will be an easy process to do next time around.
Live Boot's Apple Mac Support:
Yes, you read that correctly. FE supports (via the magic of Virtual Box) booting of Apple disk images.
Again, at this price point I am stunned.
Take a look at the screenshot carousel below - to see that in action with the relatively recent High Sierra (10.13) running.




Gotcha!: Be careful when launching LiveBoot - especially when it comes to memory allocation. Setting this too high will result in errors from Virtual Box - where it cannot secure enough memory from your analysis workstation to feed the VM (if your machine is short on ram (less than 16GB installed). Also don't set this too low, as that will cause instability within OSX and cause it to crash.
I found the sweet spot to be 4.5GB of RAM assigned to the VM for this particual version of OSX, but newer versions are likely to require more (but no more than 8GB). Obviously the VM will run like a sack of potatoes with so little RAM, but remember you are just investigating an image - not using this day in day out.
Don't Get Too Carried Away - There Are Limitations:
When I attempted to use Catalina (OSX 10.15) I received an error "No boot device" take a look at the carousel of screenshots below;
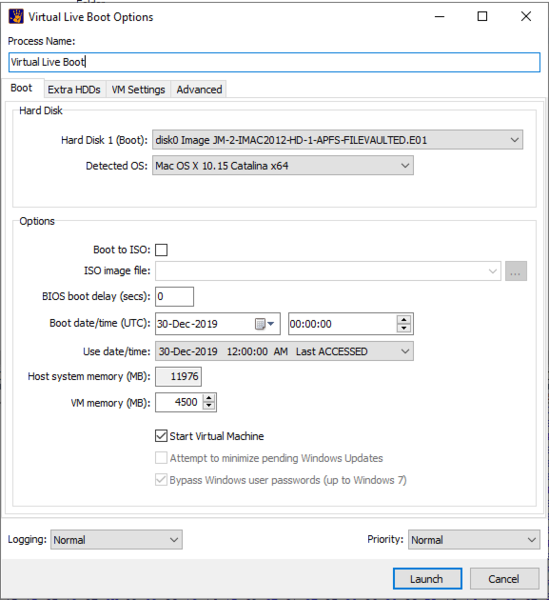
This is not FE's fault, this is a limitation of VirtualBox! Furthermore, FE states clearly in the manual that only HFS volumes are supported. But you know me, I thought I would try it anyway to make the wheel fall off.
At present VirtualBox does not have the capability to boot APFS formatted disk images "out of the box" (VMWare does by the way) so unfortunately it is unlikely that you will be booting many contempary Mac images - as anything new from Apple since around late 2018 onwards with an SSD and Mojave (10.14) was APFS by default. Machines with the OS installed onto a mechanical drive are most likely still using HFS+ - so you may get lucky an be able to boot them.
There are some rumours floating around that relate to the injection of drivers and modifying the EFI area, but those may be dead ends - GD support or Google are your friends on this one!
Deployable Live Boot:
The last trumpet that LiveBoot has to blow, is the fact that it can make a deployable disk image, which in English means you can put an entire disk image onto a USB hard drive (or memory stick) and allow a non-forensic person (for example a lawyer or a law-enforcement officer) to click an icon and boot up an image so they can rummage around and carry out their own investigation.
This does require a little bit of tinkering from the examiner, to make this happen, but it is extensively documented in the excellent FE manual, so its easy to set up.
This is a nice feature to round off the very well implemented LiveBoot feature - its a lot of work to make things like this work - so again, kudos to GD for its inclusion.
Live Boot Section Summary : EXCELLENT - The LiveBoot function of FE worked really well for me in testing, I was a little skeptical at first - as I know that making this work seeemlessly for the masses is not a simple task.
18. Testing - Indexing Engine:
A major feature of FE is that it has an indexing engine, thankfully this is not something that GD have cobbled together, they have implemented the venerable DTSeach - if you fancy a read on that technology, go here as you have been using it for years in virtually all forensic software with an indexing function.
A lot of developers moved over to ElasticSearch, which is an alternative (and much faster), if you fancy reading more about it, go here but its not something GD are planning to do anytime soon.
I would imagine GD purchased the distributable licence for DTSearch, which runs at about £10,000/$12000. If you are interested in DTSearch pricing, go here (you sad sad person :) ).
At this price point, again, I'm impressed that this is even included - there is quite a lot of work creating the back end (databases and the like) for indexing, so to see this here is interesting. I will be interesting in seeing what this can do.
FE also sports "live indexing" (on demand searches of selected files that have not been index), so if you can't wait around for a standard index of the entire file system to complete, you can run searches across a sub-set of files you specify.
No OCR Capabilities:
What did you expect at this price ? GD inform me that they considered OCR but decided against it as they had other priorities. My advice to them is change those priorities and get that feature in here - even if it adds a little to the price tag.
Indexing in Action:
So for testing, I have an image of a laptop computer, running Windows 10, the drive in the laptop was an SSD and had a capacity of 280GB.
Being an SSD the quality of data that is going to be recoverable from unallocated space is going to be very low and "bitty" as I would describe it. So for this particular test, it was skipped.
Protip: Historically, data was mostly stored in 512 byte sectors on mechanical hard drives of old, along came SSD's and they don't have any concept of sectors, they use blocks of memory to store data and essentially emulate/translate sectors for the file system to use. With a hard drive, under most circumstances (ok, sometimes armchair experts..) the data was written to contiguous clusters of sectors on the disk, meaning if you deleted a 500kb JPEG file and its directory entry, chances are that you would be able to immediately retrive the whole file by searching unallocated space for a header and a footer as the data was stored in that way in one contiguos set of clusters.
With an SSD, you will be lucky to see any more than a single block of a deleted file, meaning if a block size is 32k, you will see the first 32k of that deleted Jpg and the other blocks that file occupies are going to be elsewhere on the SSD's flash memory or possibly returned as zeros (which also means you are not going to find the footer "near" that initial header you found). This does vary between manufacturers and SSD controllers, but next time you attempt to recover files from unallocated space on an SSD and see truncated files everywhere, this is why. If this concept interests you, read this article here!
Indexing is not Configurable via the GUI:
There is little in the way that you can easily change in relation to how indexing is done in FE, there is no way that you can change noise words for an example via the GUI, you have to edit messy text files and manually add and remove noise words.
Fine for the tin-foil-hat brigage, but for newer investigators or those unfamilliar with text config files - it is going to be easy to put a character in the wrong place in these files and bork your indexing in some way - receiving undesired results.
In my opinon, urgent work needs to be done here to give the user a simple interface where they can tweak the indexing to their needs - or accept the defaults. A simple dialogue box that alters the default parameters sent by FE to DTSearch is all that is needed and that is something any decent dev could knock up in an afternoon with a few cans of full fat mountain dew.
This would move up FE's indexing game from "it works" to "it works and is really configurable".
Ok, Lets Search For Stuff:
Searching can be as basic as stuffing a single word into the search box, or you can use some expressions that FE has listed in the user manual for finding particular words in proximity to others, its also possible to use wildcards (*) when searching.
There is also the ability to extract all words from the index to a text file, so that they can be used as a dictionary attack (using 3rd party tools) for any passwords you may come across (such as logon passwords as an example).
Foreign Language Support:
FE's indexing engine also supports many foreign languages - including cyrillic ones, I did some limited testing in this area and basic searches worked fine for me.
That's a real bonus to the package - as until relavitely recently, indexing and searching of these languages has usually been reserved for E-Discovery platforms and associated tools.
Take a look at the carousel below to see basic French, Arabic and Russian searches in action.



Indexing is Not Fast:
Sadly, the indexing in FE won't win any awards for speed, GD tell me that they don't have much control over what speed the indexing runs at. Switching into geek mode, I had a look at CPU core usage and found that FE was indeed using all four physical cores on my CPU (although the log files state it is using only 2), but was not maxing them out - neither was it anywhere near filling my hard drives command queue or the SATA bus it was connected to.
Perhaps this is something to do with the way DTSearch is implemented, but at this price, at the moment - I am not complaining.
Limitations of "Hit" Counts:
I an into issues with searches that returned a lot of hits, for example, an insane search for "windows" gave me 9,000,000 hits (not responsive files - that count was much lower), FE refused to display any of those hits or their containing files and had no warning onscreen stating that this was an excessive amount of hits.
This is something that needs to be redressed, with the limits clearly shown onscreen or listed in the manual.
Winding down to a slightly less insane search with 1,000,000 hits (again not responsive files - those were much lower) FE gave up and yielded nothing for me to view.
I finally entered another search which returned 300,000 hits and this seemed to be something that the indexing engine could handle and a list of responsive files was displayed. Finally I was able to start applying further filters to reduce those hits down to a managable number of reponsive files.
What is interesting here is that the insane 9,000,000 keyword hits are actually in the DTSearch index that FE has created on the disk, it just that FE can't display them. If you ask me, it is either a licencing or programatical reason why FE can't show this many hits.
Very Low Limit on Responsive Files:
So after our short journey to cuckoo-land with silly limit testing searches, lets come down to planet earth and look at what really matters, the number of responsive files FE can handle from a search.
I found that there is some form of hard limit of responsive files, any search that returns over 100,000 responsive files would simply cause FE to stare back at you and display an empty search results window - with no error (that needs fixing).
99,999 reponsive files and under was fine and FE worked as intended. This is an extremely low number of hits, especially in cases where there are potentially hundreds of thousands of E-Mails in the E-Discovery universe to be searched, before they are ingested into a viewing platform.
So this limitation of FE's engine would cause me problems with my workflow. A dealbreaker ? Maybe, but if you change your workflow (such as adding more keywords to reduce the responsive file count to below 100,000), not really.
The usually super-detailed manual does not give any details on the "limitations" of the indexing engine, which in this case I think it should - a number of other tools that I can think of will warn you on-screen if what you are about to start a dumb-ass search that is going to take a very long time.
In FE's case, they need a warning to let you know that you can't view any search result that has over "x" responsive files.
This way, you can work around these limits and not waste precious time with searches that you won't be able to see the results for.
This is Why We Cull Before We Index:
So, to the examiners out there who are still learning the ropes, the above little demonstration of how you can quickly bring an indexing engine to its knees. This hopefully shows you that the concept of "culling" the contents of a disk image is vital for your workflow.
Culling is the process of identifying all files on the disk image that can contain user data, they form two distinct categories. EFILES and EMAIL. The former being any file that is not EMAIL.
At the risk of over-simplifying culling, you would expand compound files, verify file signatures and then come up with a list of file extensions/signatures that you want to include in your investigation. Such as .docx, .xlsx, .pptx, .pst, .ost and so on.
Once these files are identified, they would be exported, enmasse, to a logical evidence file (such as an .L01 for Encase lovers or a .AD1 for incompatibility lovers). Once done, those files would be added back into a new case within FE an then the index searching could take place.
This way, you don't have 6 million hits for the word microsoft (as system files are not in the culled file set you are examining), and the indexing engine does not fall over because you are asking too much of it.
So remember, CULL first, then INDEX and then SEARCH in that order.
This is not advice, but just one way of doing things - some organisations still ingest complete disk images - but those packages are built to handle crazy large data sets and enormous numbers of search hits and reponsive files.
File Searching Overview:
Happily I can say that the implementation of DTSearch in relation to actually finding the keywords you typed in has not been cocked up, FE found most of the tricky things I buried away in obscure files. Databases were parsed, even Microsoft One-Note .bin files, word .tmp files and a whole host of other files were examined by the indexing engine so this is a good overall result.
So that's EFILES done, lets take a look at E-MAIL indexing....
E-Mail Indexing:
As we know, FE works on the "Tell me to do something, in minute detail, then I will do it" principal, this means you have to "Add" any E-Mail that you want to index into the E-Mail module before the indexer will give it the time of day.
Again, this is not a beginner feature and requires a robust workflow to be set up before you even attempt to index E-Mail, there is no 21st century automation here, we are in days of Norton Disk Edit here, you have to do everything yourself (but you are 1337 so thats fine!).
A good workflow for FE might look something like this;
1.) Recover folders (recover deleted files still referenced by the file system)
2.) Carve unallocated (find deleted files no longer referenced by the file system)
3.) Verify file signatures
4.) Expand Compound files (verifying signatures of newly extracted files)
5.) Sort the file list by "Signature"
6.) Select all of the loose E-Mail messages and container files
7.) Right click those and add them to the E-Mail module
8.) Enter the Indexing module and choose to index all data you just added to the E-Mail module.
It is processes like this that some examiners may miss a step, because frankly thats a lot of steps to carry out in the correct order to maximise the detection of file types.
Indexing Needs to be Automated:
I think a great addition to FE, to bring it inline with other "mainstream" forensic tools, would be improvements to its evidence processor window (see a side by side comparison below).
There is no way (that I could see) to index files automatically as are they ingested, instead we have to go through a series of repetitive steps that don't scale well, even on small cases with say 50 custodians. This is something that sticks out like a sore thumb and urgently needs a band-aid.
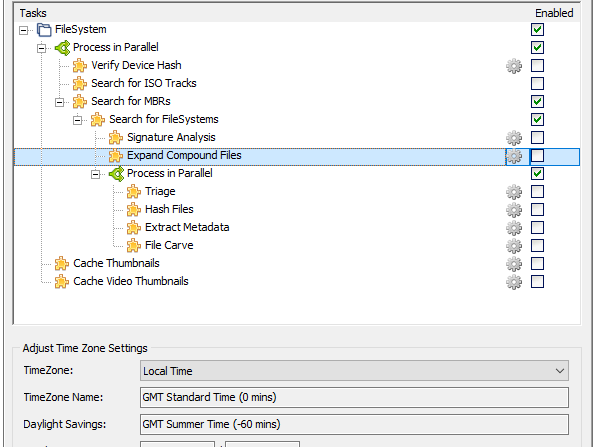
FE's Evidence Processor Dialogue (sans indexing)

(FTK) Evidence Processor Dialogue with Indexing
E-Mail Indexing Speed:
Indexing of E-Mail is quite fast relatively speaking, it took FE 8 minutes to parse a single .OST file which contained 48,695 items with a file size of 3.35GB. So extrapolating (guessing) that out takes us to 33.5GB an hour, which on a single processor machine running on non-raided SATA mechanical disk drives is enough performance for a product at this level of the game.
No complaints from me here then.
System Resource Consumption Whilst Indexing:
Lets take a look behind the curtain in relation to what resources FE is using during indexing.
You can take a peek at the carousel of screen shots found below.
Memory usage is extremely low when indexing E-Mail, 380MB when I checked it, we also see the mechanical disk is getting a work out (its queue length hovering around 4 - meaning the indexing process is requesting operations to be carried out faster than the drive can respond) a switch to even a cheap nankang bitloser SSD would see this bottle neck eliminated.
ProTip: Don't use cheap SSD's, decent brands please (with good 4k read/write performance).
For indexing EFILES, memory usage peaked at 1.2GB and disk usage was somewhat higher - nothing here to worry about.
CPU usage was for the entire indexing run below 60% which means that you would easily be able to use the machine for other light tasks whilst FE is indexing in the background. Remember we are testing on some janky old quad core i5 with about 12GB or RAM so these numbers are respectable!




I'm happy with the resources it uses, if you want everyting indexed at 100 to 250GB+ an hour, you need to go and spend big money on a decent server and something like Nuix!
Indexing Section Summary: VERY GOOD - With a 100,000 limit on reponsive files, this could pose a deal-breaking problem to some users - for others its a simple change of workflow.
19. Testing - Anti Virus Scanner:
Another interesting - and dare I say unusual - feature of FE is the built in Virus Scanning engine, this allows you to scan the contents of any files currently ingested into FE for for the presence of any detectable malicious programs. This sounds good in principal (its a matter of course in my lab that all data is thoroughly virus scanned), but lets pull back the layers on this and take a closer look.
The carousel below shows you the options you have for virus scanning and the auto-update system, this is very cleanly implemented - I like what I see - this would be a reason to own FE on its own, as it would save me masses of time - but more on that later in a Protip.



ClamAV (Which GD have chosen to implement) is possibly one of the weakest scanning engines I have come across in my experience with virus, trojan and malware analysis - I've dissassembled many malicious binaries in my time, so I like to think I know at least something about the antivirus engines and how they detect malicious binaries, scripts or "file-less" registry based code.
In so called "independant testing", ClamAV scored a detection rate of 75%, whereas the full fat "paid" products in the test detected up to 85% of the real-world samples, interesting reading if you believe it. You can read more about ClamAV and this test here.
Lets Take ClamAV For a Test Drive:
I thought I would raid a collection of known malicious programs - 23 in total, they included contemporary Ransomware, Password Stealers, Crypto Lockers, Banking Trojans, Backdoors, Adware and Riskware - a real cauldron of nasty stuff that would give anyone a really bad day if they infected your machine. Nothing here is hard to detect - hashes or positional byte signatures would do just fine. If you are interested in reading a bit more about virus signatures and how they work, check out this article.
I updated FE's ClamAV to the latest version (a single click from within FE - check out the screenshots in the carousel below) and imported my logical image file (.AD1) with these 23 files stored inside. This was totally painless and worked first time. We are off to a good start.
ProTip: There are all sorts of arguments about having forensic analysis workstations connected to the internet - in my experience a lot of people think its all fine, then they realise it was a bad idea when their organisation is compromised (hacked) using some zero day exploit and your clients data is stolen. You only have to look here, to see how prestigous law firm Grubman Shire Meiselas & Sacks was compromised and all their client data stolen. If you do connect your machines, have a protocol in place to minimise data stored.
Use a Potatoe to Scan For Malicious Programs:
In my lab I have a separate potatoe machine which is devoid of client data and used to scan the disk images that arrive as part of investigations. This machine is momentarily connected to update virus detection databases (before client data on external USB drives is connected and scanned). You don't want to be doing these scans on your forensic workstation as running persistant AV or Antimalware on those machines is a minefield and an article in its own right.
The other much more efficient method I use is simply submitting all hashes from culled data sets (not every file on the drive) to a threat intelligence network (such as VirusTotal) using an automated script that simply tells me if anything bad is found.
Using a potatoe is a cheap and cheerful way to avert risk, it works for me, but others may disagree and rely upon their IDS, Firewall or tin-foil hat to protect their permanently internet connected systems from compromise. I sleep well at night using my method.
Telling FE to scan the test files them gave the following results;
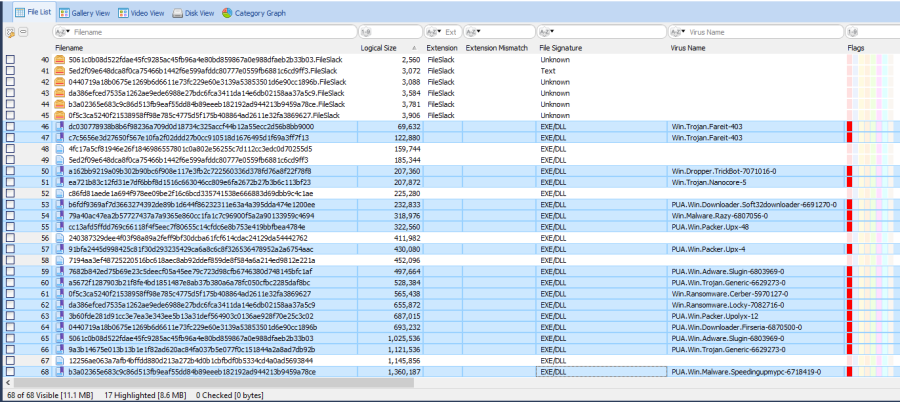 ClamAV Detections 73% - Click to enlarge
ClamAV Detections 73% - Click to enlarge
As you can see above, in FE's really nice and clear GUI (I like it, so I'm not going to shut up about it!) 17 of the 23 files were identified as being infected (the Virus Name column is populated and each file has a red flag) thats just 73% - about how I expected ClamAV to perform.
When we scan these 23 files with a really good (and free) anti-virus engine from Avast in the Czech Republic - all 23 are identified;
 Avast AntiVirus Scan Results 100% Detection Rate
Avast AntiVirus Scan Results 100% Detection Rate
So we can see that from these results, for me, there is no point in using ClamAV as I know it is going to miss what I call a large percentage of malicious programs. A half baked scan is of little use in my opinon.
If I was a developer at GD, I would be looking at licencing the engine of a decent AV and Malware tool, on a royalty basis which would make this a must have feature (as you would have maximum detection capability out of the box).
Sure there is cost associated with that, but with vendors peddaling out their AV solutions for £20/$25/€23 a pop to consumers for a single licence, its not complex math to work out that this is not going to put the price of FE up by much when factored into how many licences FE would purchase in bulk!
Alternatively implementation of a commercial API provided by an intellegence network would be a great "optional extra" for FE to implement. I'd happily pay a premium on the licence price to bolt on this functionality and save hours of lab time. Right click and send hashes (en masse) to the private/paid API of virus total for example (not that it is the best out there).
ProTip:
The cleanest way (in my humble opinion) to scan for virus and malware is to mount your disk image of choice as a physical disk using Arsenal Image mounter (free) or Mount Image Pro (included with FE), then ensure that "all" files are scanned and that any sensitivity settings are set to maximum - then run the "offline" scan.
It is also really important to enable verbose logging when you are scanning mounted disk images. The NTFS file system uses reparse points (extensions to the file system) and other "pointers" which can confuse some virus scanners.
When this happens, it is possible that the virus scanner starts scanning the files on the machine being used to do the scan - or it states the scan has been completed yet it has skipped a bunch of files. So always compare the number of files scanned (from the AV log files) to the number of files you expected it to scan - to ensure anything strange is detected and no files escape a scan! This may seem like a ball-ache, but if you are serious about scanning, you need to check the logs.
I personally scan disk images with two different AntiVirus engines along with a third Malware specific engine.
This way I can report back to client that a "thorough scan" was carried out and then offer them the option of doing additional RAM image analysis to look for memory resident programs that are not detectable on the disk during an offline scan.
Offline scans won't usually catch anything polymorphic (where its hash or AV signature is unique) or anything that is "file-less" and resides in the registry. To catch these advanced critters, you would need to use the LiveBoot function of FE to boot the suspect machine up, log in as the users and image the machines RAM for each user. Once you have the RAM Image you can analyse it with a compromise detection tool such as Volatility (open source) for Indicators of Compromise (IOC).
Virus Scanner Section Summary - Below Average
This is a great idea, I really really like it, but sadly its not something that I would be happy to use on live cases due to the miserable detection rate ClamAV has.
With a bit of work, this would become a killer feature and would stop me messing around with mounting images and using a separate machine to scan all disk images that come into the lab.
I would be happy to pay more for this feature, maybe you would too.
20. Testing - Windows Registry Parsing Module
So FE has a rather comprehensive registry parsing module - its a dedicated tab within the interface.
To manage expectations, its no IEF or Axiom (remember, FE is not for those wanting to be spoon fed), but it is present.
As with FE's core principals of operation with EFILES and EMAIL, you have to manually add the registry files into FEs' dedicated registry module before you can run any of the baked in scripts to parse the registry.
I'd like to see some form of automation here were the user can tick a box and all registry files are automatically added to the registry tab - the user can then choose which registry to parse for artefacts.
The carousel below shows you what the registry module is capable of, at a quick glance this looks really comprehensive - so lets dig in a bit deeper.



Not Beginner Friendly:
Beginners in the field will need to really be on their game here - as they will need to know exactly which registry files to import here and from which users.
GD will argue that it is possible to parse parts of the registry directly from the File System tab, with no knowledge of registry files required by the user, but this is a messy implementation and the functionality provided by this "Quick Registry" function is rudimentary at best.
The Quick Registry function is not consistent with what can be found in the registry module (the quick registry function has a fraction of the capabilities of the full on Registry Module).
My advice to GD is to implement the quick registry functionality directly into the registry module, so the user simply has to click a button to parse all registry files (or those that they select) without having to go and manually find each and every one.
Old, Confusing Registry Artefact Parsers
The registry parser has not seen a lof of love from the GD developers in recent times.
What is there is poorly labelled and often only works on ancient versions of the Windows Operating System.
Too many times I would run a registry artefact script (from those listed in the carousel previously) only to be told "No Key Found".
This reminds me of the loss of focus I saw earlier in the Artefacts tab, where we have a rag tag collection of scripts that don't give any detail as to what they collect or what versions of Windows they are compatible with.
For the most part, it had me yelling at the screen and opening up regedit to check each and every result that FE was telling me. That's not a good place to be.
The usually excellent manual makes a pretty weak excuse that registry values and locations often change and that the output from the registry scripts may be inaccurate - that's a total cop out. Thats what we are paying SMS for, so that someone, in a broom cupboard at GD regularly revisits these scripts when a new operating system drops or users report something is not working as intended.
Consistency Issues:
I also saw inconsistency creep into the registry module, which is a common trait of FE. Perhaps they have different developers that handle different modules ?
The "Artefacts" tab has very convenient "Parse All" option, which allows a one click extraction and parse of available data.
The "Registry" module sadly does not have this feature - instead it requires the examine to painstakingly run each registry key parser in turn if you want a complete picture of the machine that you can skim through for anything interesting. As with many things in FE, this needlessly does not scale well for cases with more than one or two computers.
With some polish (updating of existing scripts and renaming them to something contemporary) and the weeding out of old scripts that no one is ever going to use again (or at least put them in a "legacy" sub folder in the registry artefact parser menu) this could be a really nice part of FE.
Registry Parser Section Summary - Below Average - This entire section appears to have been forgotten/abandoned, its out dated, deviod of basic automation and in need of some urgent updates. Another blow to what was shaping up to be a really powerful forensic suite.